

课程简介
这是一门面向大模型 Agent 后训练与强化学习落地的系统实战课。
课程不只讲 RLHF、PPO、DPO、GRPO、RLVR 的算法概念,而是围绕 Agent 项目真实落地中的奖励设计、信用分配、长轨迹归因、训练系统、评测反馈和 Skill 自进化展开。你会把论文里的方法、开源项目里的实现和工业场景里的工程判断串起来,形成一套可复用的 Agent RL 落地框架。
从 RLHF 到 Agentic RL,系统理解奖励、偏好优化、Verifiers、PRM、GRPO、VeRL 与训练系统。用 11 章主线 + 6 个项目实战 + 源码拆解 + 论文地图 + 持续更新的学习宝典推进。
课程方法论
同一条闭环里讲整套链路 —— RL 基础、对齐、奖励、信用分配、训练框架、沙箱、异步系统、评测放在同一张工程地图上推进,让你看清模块之间的协同关系。
沿源码、部署、训练、推理、评测拆到关键链路 —— Reagent、VeRL、DeepAnalyze、OpenClaw-RL、Memento-Skills 每个项目都走到代码、配置和调用顺序层。
用 260+ 篇论文建立长期选型地图 —— 把 PPO 改进、DPO 攻防、GRPO、奖励建模、训练系统和多轮 Agent RL 重组归纳,随研究进展持续更新。
🔔 如需通过淘宝或微信支付,请点此查看【通过淘宝或微信小店购买】。
配套《Agentic RL 学习宝典》
这不是课程原始资料的简单打包,而是在课程配套资料基础上额外提供的在线学习支持。你可以随时查阅核心知识点、章节补充、代码说明、常见问题和前沿论文梳理。
Agent RL 变化很快,真正有价值的是持续更新的学习系统。知识库会随着课程推进、论文进展和项目问题不断补充,帮助你在学习过程中持续获得新的参考和指引。

官网课程页面已同步更新课程配套资料与知识库文档。为了方便大家更灵活地查阅学习资料,我们也同步整理了飞书知识库,内容与官网知识库文档完全一致。
通过官网购买课程的同学,在享有官网课程学习权限、课程配套资料和官网知识库文档的同时,也可根据需要联系课程助理开通飞书知识库访问权限。

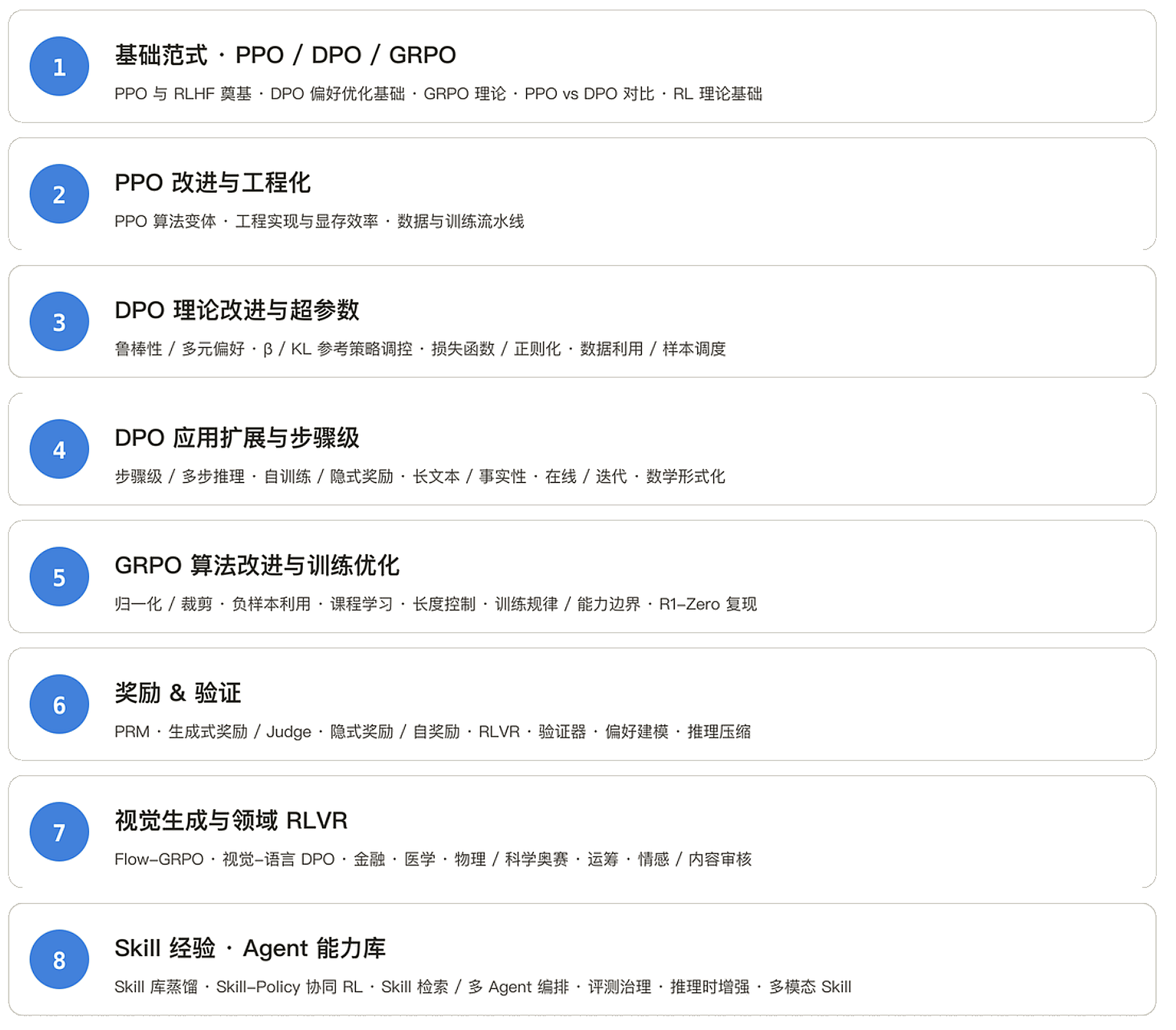
配套《Agentic RL 论文地图》
260+ 篇论文的结构化梳理,按算法家族 + 工程主题 + 领域应用 + Agent 能力库四个维度重新组织的论文地图。
读 RL 论文最大的问题不是数量,而是没有挂点 —— 每周新出的 PPO 变体、DPO 改进、GRPO 优化、奖励范式、Skill 自进化方案,缺少现成的对照系,越追越乱。
地图把 260+ 篇论文按上述四个维度归到 8 个一级类目、40+ 二级子主题里,给每篇论文都先找好坐标;再出现新论文时,你不需要从零理解,只要判断它在地图上挂在哪一格,再决定是否细读。
四个阶段,把 Agent RL 串成完整闭环
阶段 1 · RL 与后训练公共语言
从 RLHF 到 Agentic RL 的演化地图开始,把状态、动作、奖励、轨迹、回报、价值函数、PPO 放回同一套语言里。这一阶段重点是搭"地基":先看清整个对齐算法家族(PPO / DPO / GRPO / RLVR / RLAIF)各自的定位与边界,再把 MDP / POMDP、贝尔曼方程、TD、策略梯度串成一条完整推导链。学完之后,你就有了和团队、和论文对齐的公共语言。
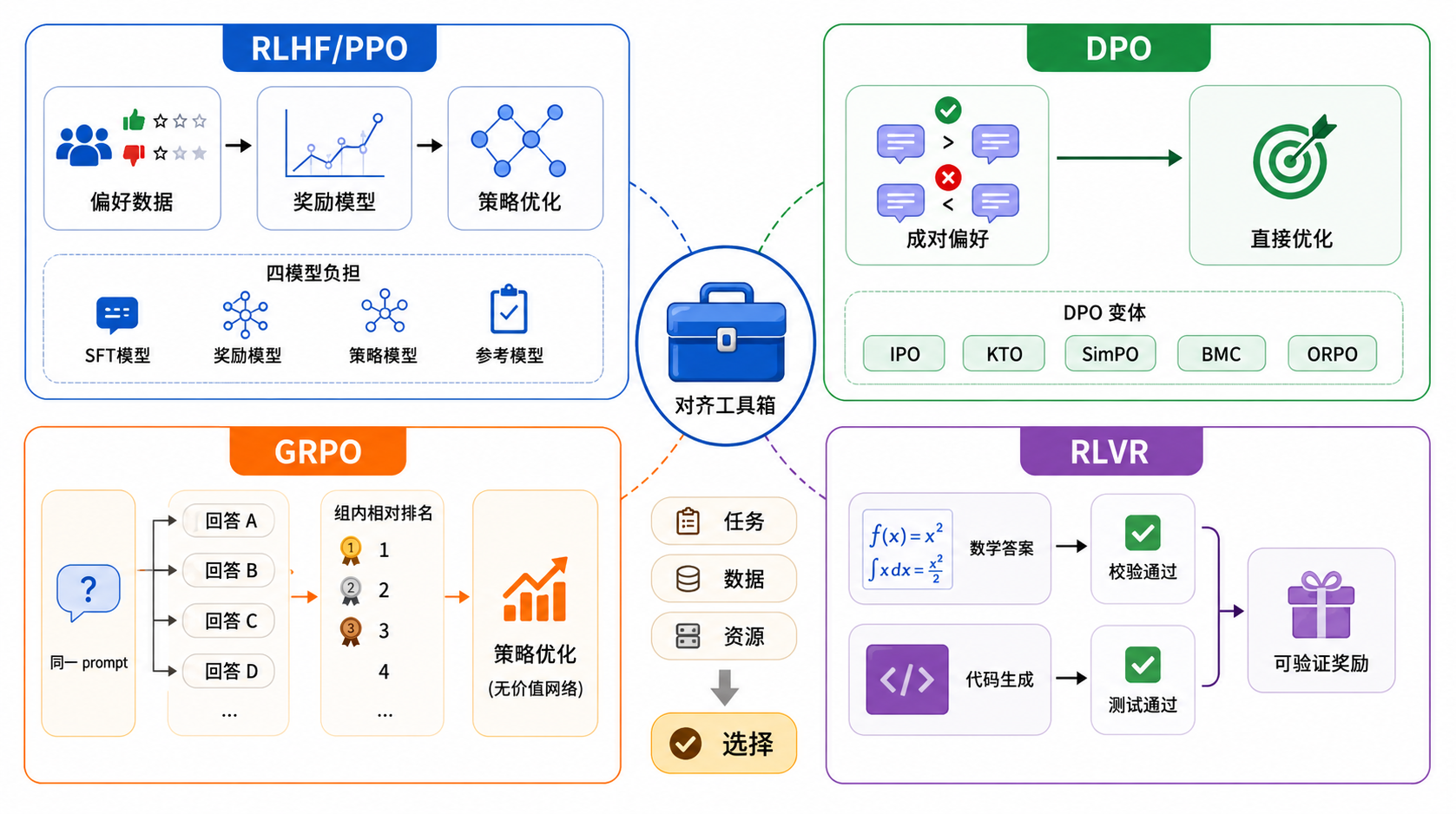
阶段 2 · 对齐、奖励与信用分配
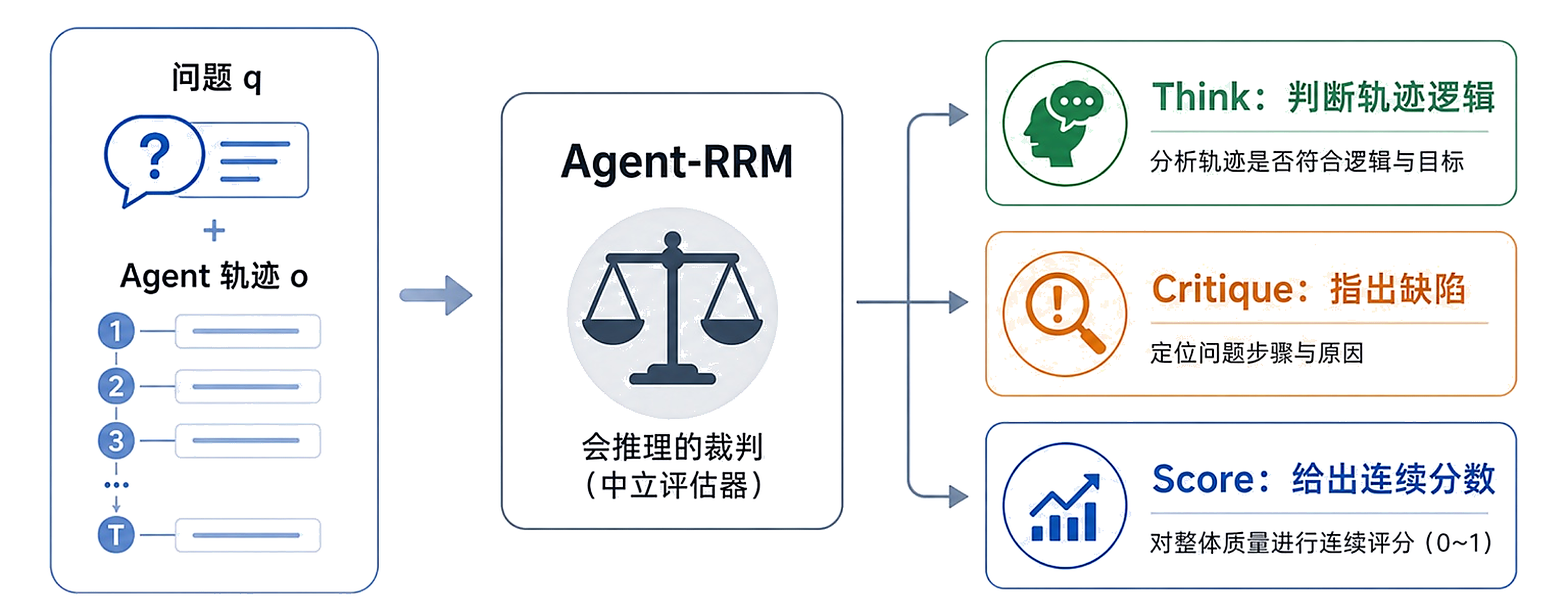
系统拆开 RLHF、RLAIF、DPO、RLVR、PRM、GRM、奖励黑客、Agent 长轨迹责任分配。从单点偏好对齐进入到结构化反馈与过程奖励,重点回答"奖励从哪里来、给到多细、怎么防作弊"这一整套问题。最后通过 Agent-RRM 与 Reagent 把长轨迹的过程诊断变成可训练信号 —— 从"最终答案给分"推进到"过程可诊断、反馈可训练"。
阶段 3 · 工业级训练系统与 Agent 项目
进入 VeRL、DeepAnalyze、OpenClaw-RL,把算法选择落到分布式训练、沙箱、rollout、评测和权重同步。读懂 DataProto / WorkerGroup / Reward Loop / Agent Loop 的组织方式,跑通从冷启动 SFT 到 GRPO、PRM+RL 的完整后训练链路,并看到一个 8B 小模型如何在数据分析任务里被一步步训出来。这一阶段帮你完成从"看懂算法"到"看懂系统、看懂训练实际怎么发生"的过渡。
阶段 4 · Skill、自进化与论文选型地图
讨论不改权重的能力增长、Skill 发现与路由、外部能力治理。通过 Memento-Skills 看到 Agent 如何从失败轨迹中沉淀新技能、评估、改进并复用;再用 260+ 篇论文按 PPO 改进、DPO 攻防、GRPO 演化、奖励建模、训练系统和多轮 Agent RL 重组归纳,建立可以长期复用的横向判断框架。Agent RL 变化很快,这一阶段帮你把"追新论文"换成"在地图上挂新点"。
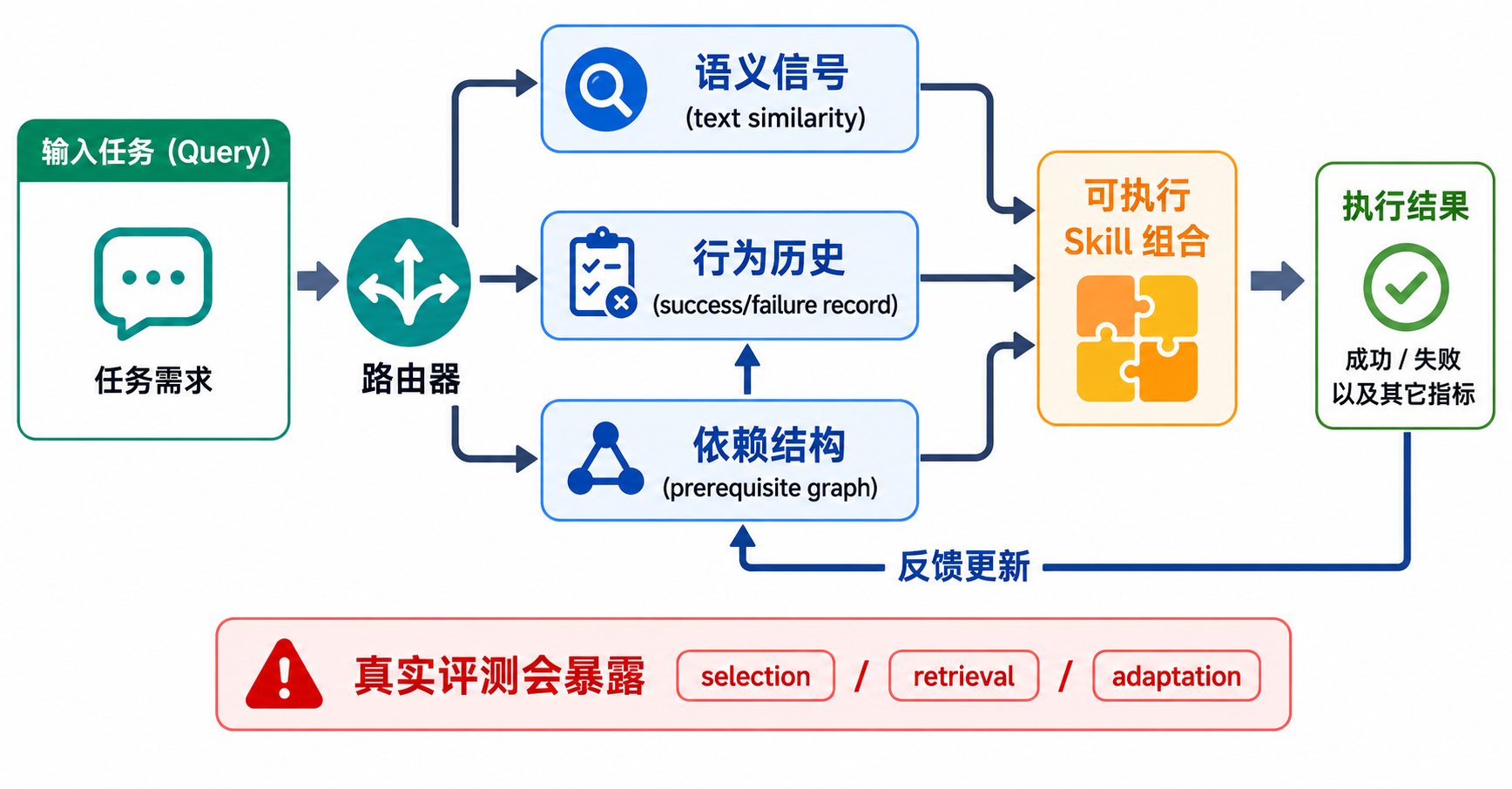
六个项目实战,跑通关键链路
每个项目都围绕环境、数据、源码、配置、服务、训练脚本、推理、评测展开,不只看架构图,也看关键链路怎么落到工程里。
项目 1 · 数学 / 代码 / 逻辑任务的可验证奖励基建(Verifiers)
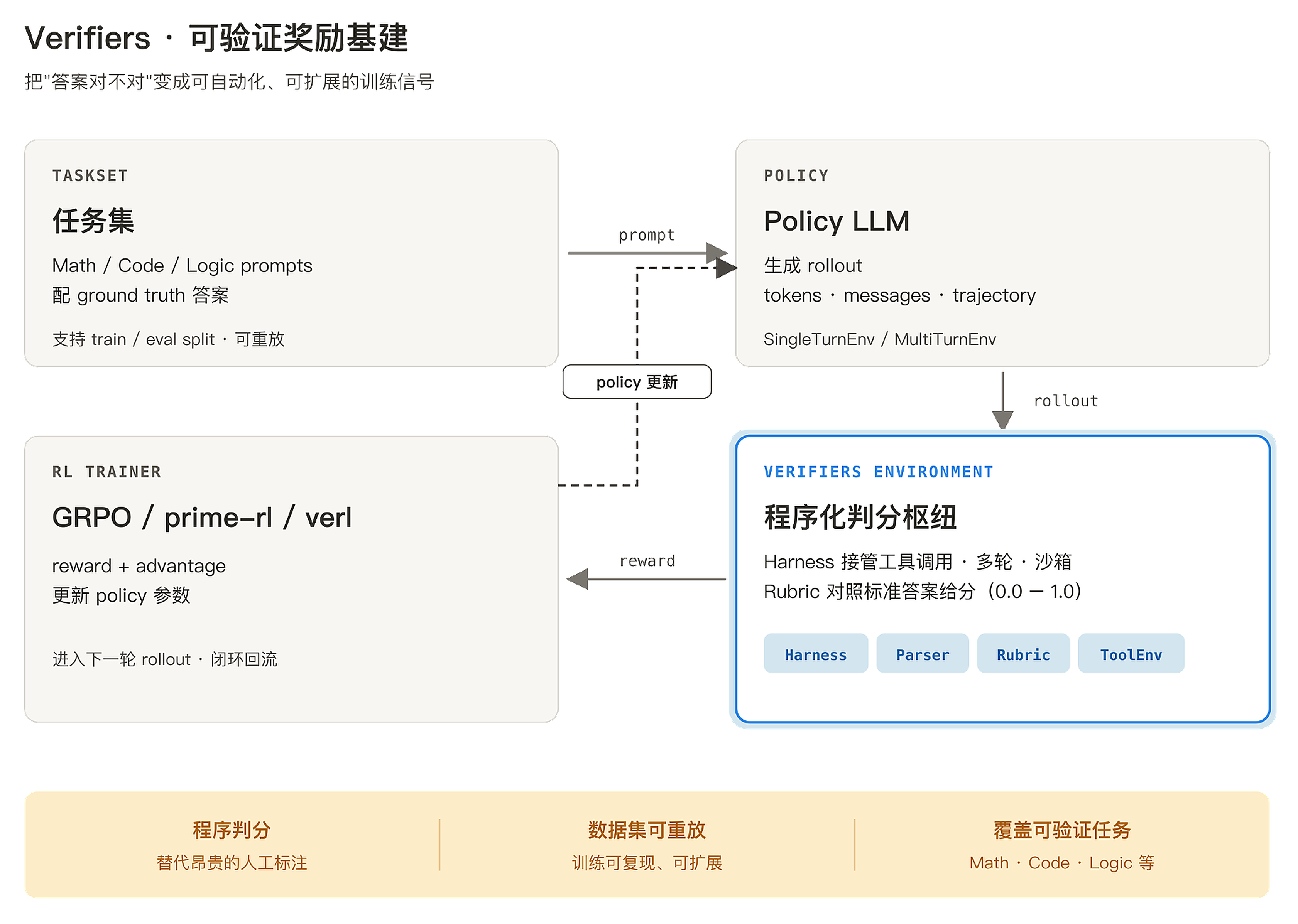
搭建可验证奖励的基础设施 —— 把"答案对不对"变成可自动化、可扩展的训练信号。Verifiers 是 Math / Code / Logic 这类"标准答案明确"任务的奖励层基建:用程序代替人工对最终输出做硬判分,再把规则化判分扩展成可重放数据集,给后续 RLVR、GRPO、PRM 提供干净的奖励来源。
- 拆 verifier 服务、规则编排、自动判分与可重放数据集;
- 走一遍 RLVR 从数据生成、采样、判分到奖励回收的完整链路;
- 为一个新的可验证任务搭出第一版 verifier,并预判它的边界与失效模式。
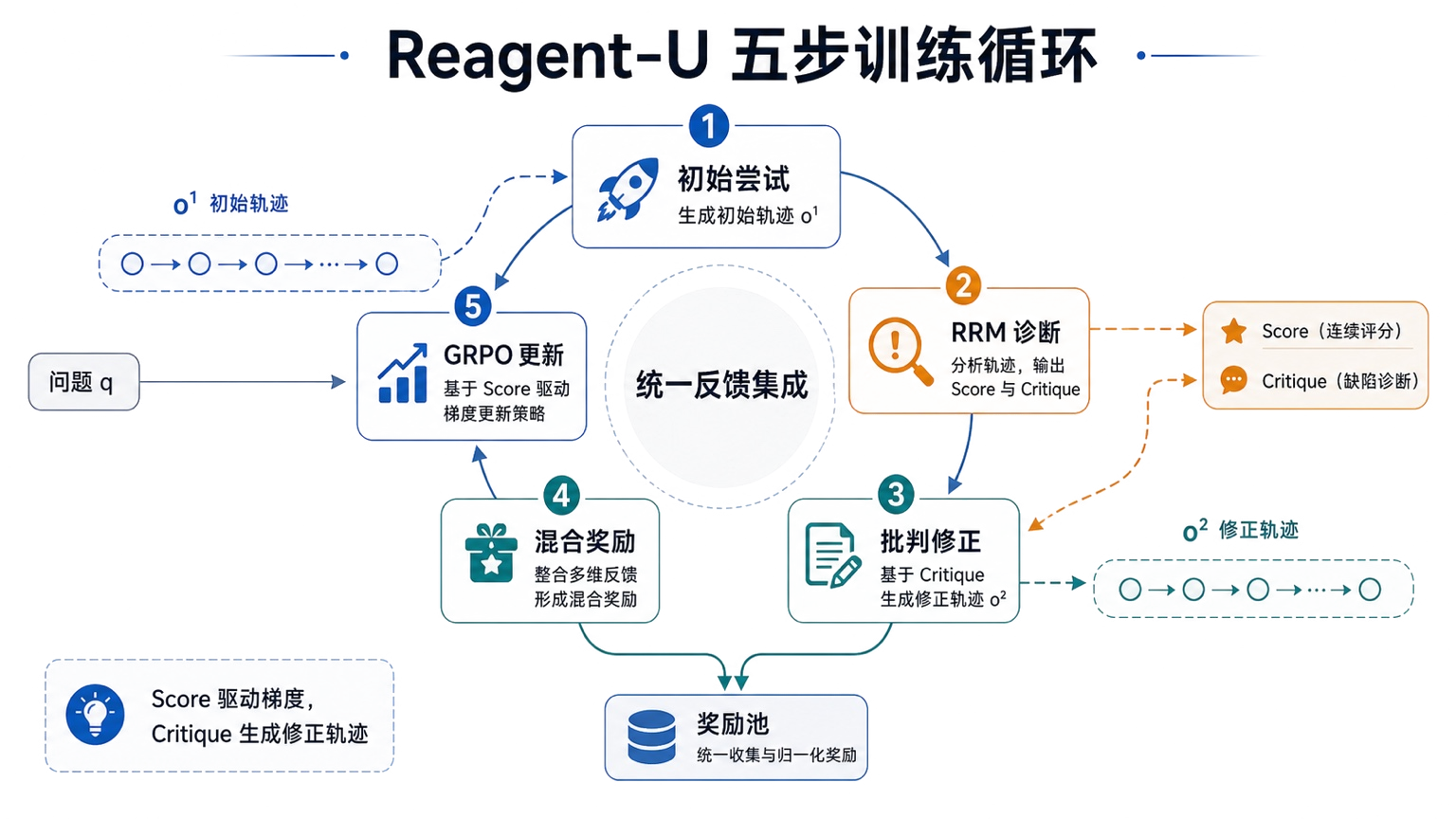
项目 2 · 多步 Agent 的过程反馈与长轨迹信用分配(Reagent)
部署 RRM,跑通 Agent SFT、混合奖励、GRPO 和推理服务,理解结构化反馈如何进入训练。Reagent 解决的是多步任务里"最终答案对/错"信号过粗的问题 —— 给每一步挂上"想法 + 批评 + 评分",让长轨迹的过程也变得可训练。
- 拆 RRM 服务、Agent SFT、规则奖励与模型奖励融合的具体接口;
- 把规则奖励(确定的对错)和模型奖励(RRM 评分)做加权融合,处理奖励冲突;
- 跑通 GRPO 训练 + 推理服务的闭环,看反馈如何回到下一轮采样。
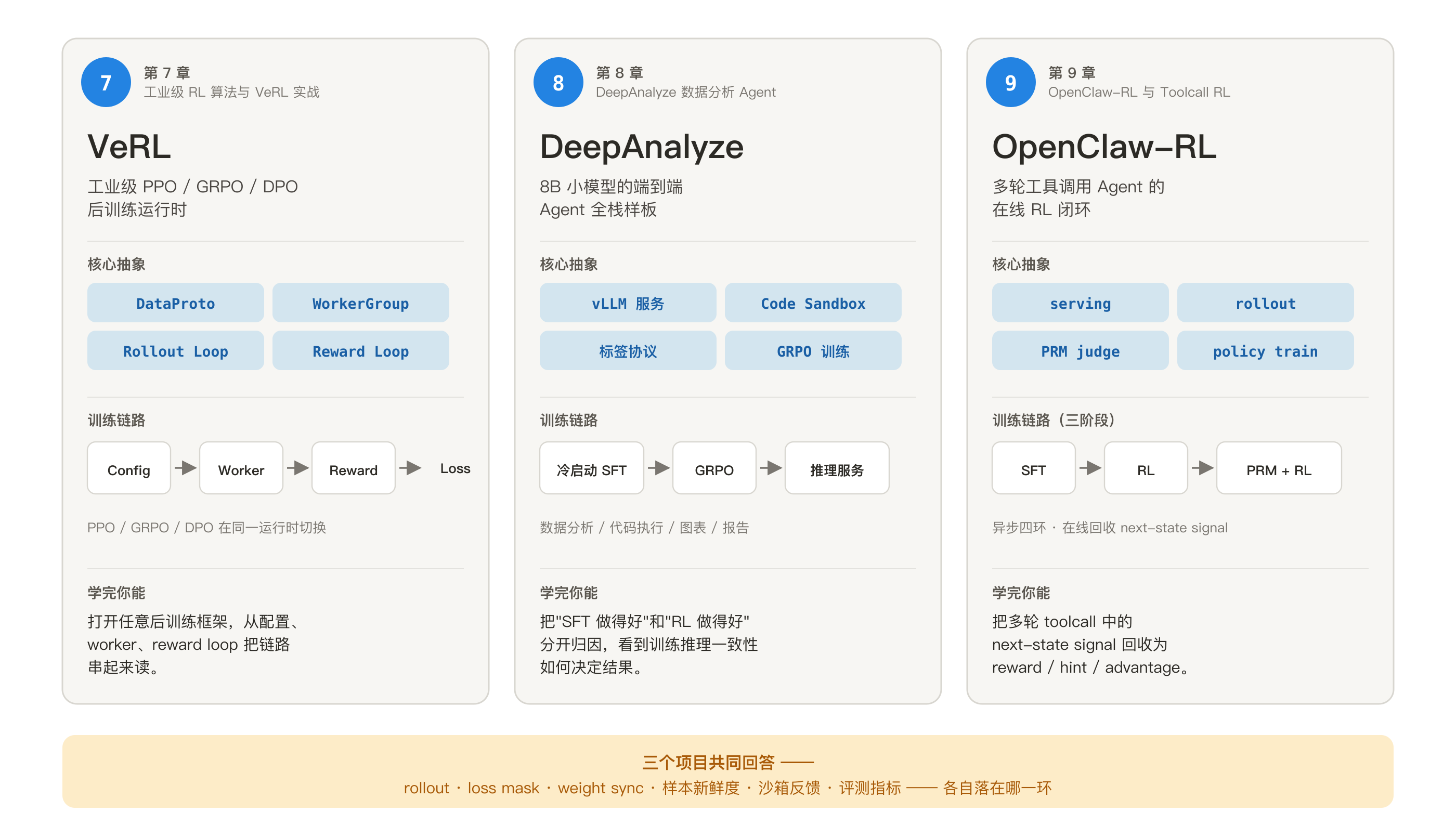
项目 3 · 工业级 PPO / GRPO / DPO 后训练运行时(VeRL)
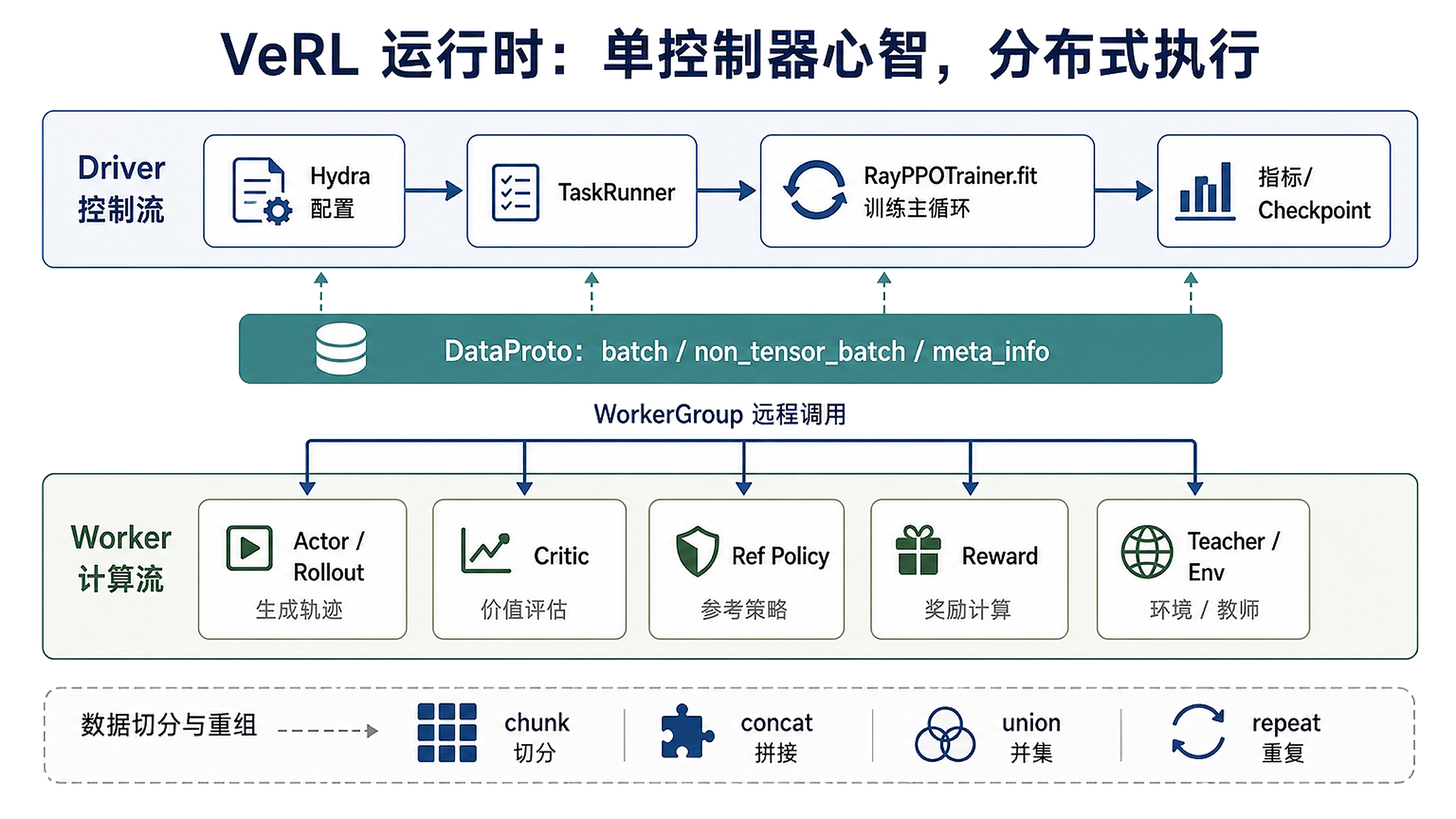
读懂后训练运行时,定位 actor loss、reward function、rollout 和分布式 worker 的关键链路。VeRL 是工业级开源后训练框架的代表 —— 把 PPO / GRPO / DPO 等算法从论文落到一个可配置、可扩展的分布式系统里,支撑从数学验证到多轮工具交互的不同训练任务。
- 拆 DataProto(数据协议)、WorkerGroup(分布式架构)、Rollout Loop、Reward Loop 与 Agent Loop;
- 在 actor loss、advantage 计算、KL 约束等关键代码位置打断点,理解参数变化的物理过程;
- 看懂 PPO / GRPO / DPO 三种 loss 在同一套运行时里如何切换。
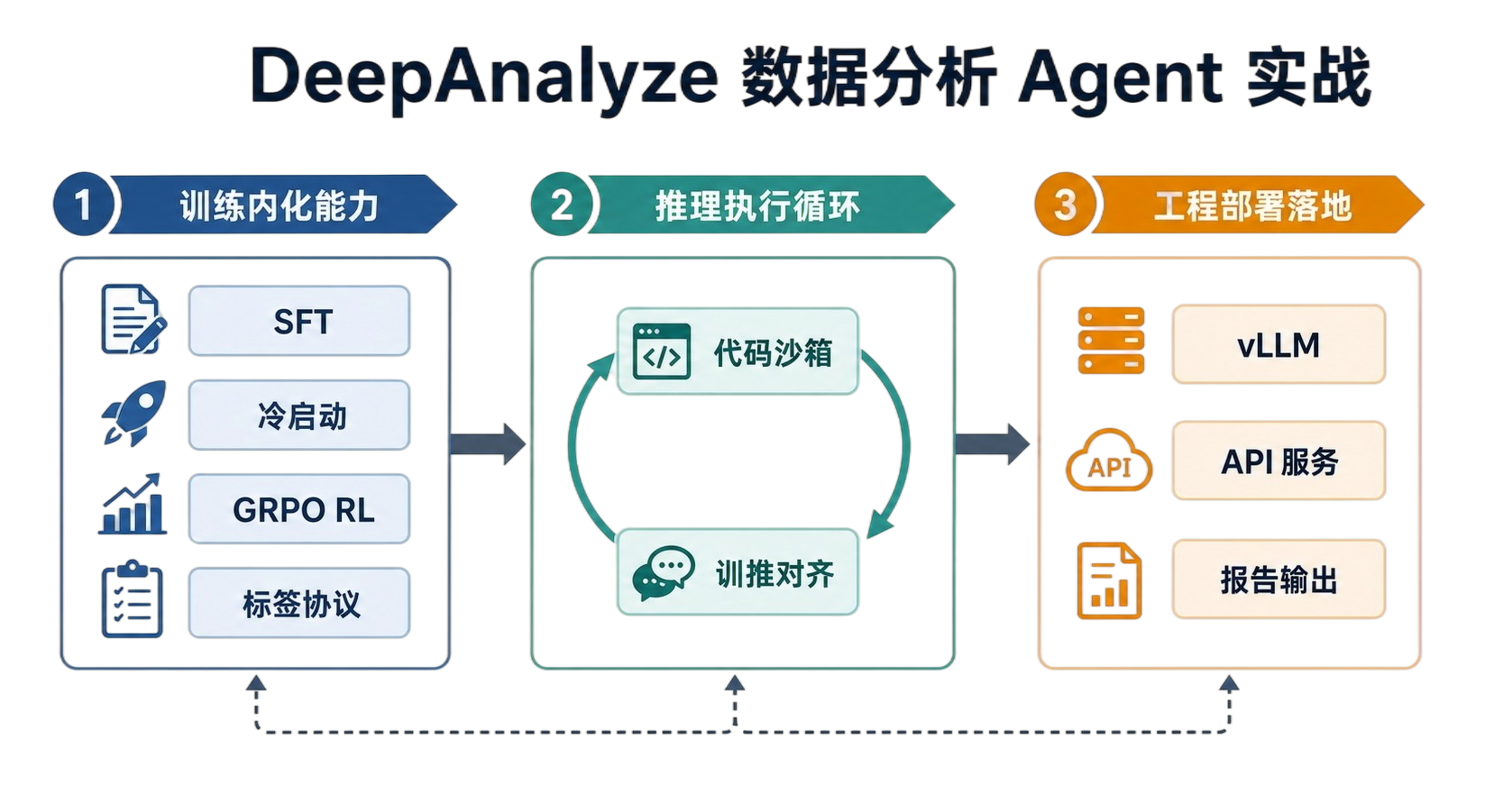
项目 4 · 数据分析 Agent 全流程对齐(DeepAnalyze)
让 8B 小模型完成数据分析、代码执行、图表和报告生成,观察 Agent 行为如何被训进权重。DeepAnalyze 是"端到端 Agent RL"的完整样本 —— 从 vLLM 推理服务、代码沙箱、前端 SDK 到训练标签协议,整条 SFT → 冷启动 SFT → GRPO 的链路都摆在桌面上。
- 拆 vLLM、API、文件服务、前端 SDK 与代码沙箱,看一个 Agent 系统怎么"长出来";
- 理解冷启动 SFT 的标签协议(思考、工具调用、产出格式)如何决定后续 RL 的可训练性;
- 跟着 GRPO 训练脚本,看奖励信号从沙箱反馈如何回到策略参数。
项目 5 · 多轮工具调用 Agent 的在线 RL 闭环(OpenClaw-RL)
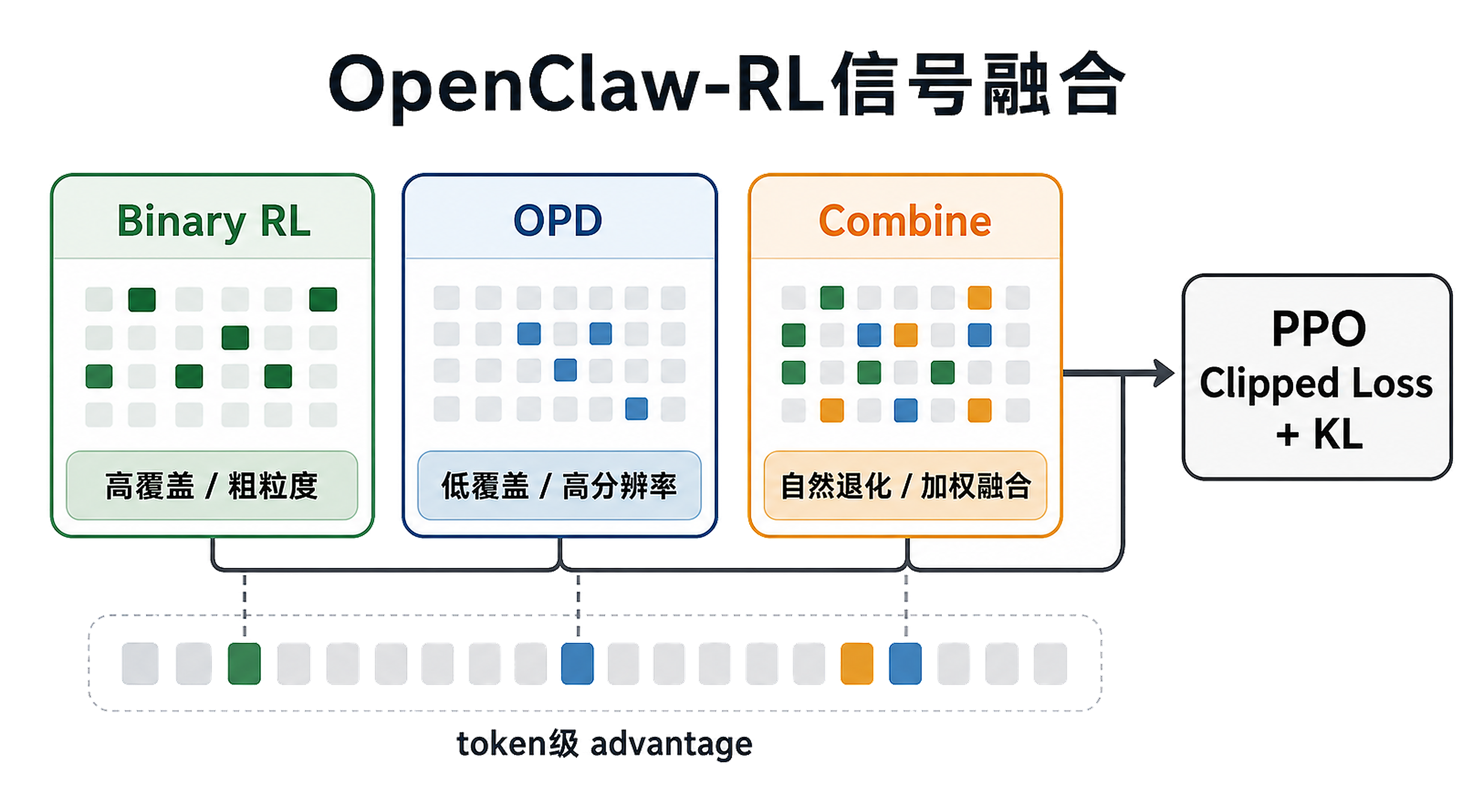
用 SFT、RL、PRM+RL 三阶段跑通 toolcall RL,理解 next-state signal 如何回收成训练反馈。OpenClaw-RL 面对的是"工具调用 Agent 在线学习"这一最难的场景之一 —— 多轮、稀疏反馈、异步训练,每一步都涉及 serving、rollout、judge、policy training 的协同。
- 拆 serving、rollout、PRM judge、policy training 异步协同的四个环;
- 定位 loss mask、session header、weight sync 与样本新鲜度问题,理解它们怎么影响梯度;
- 看二元奖励(最终对错)与 OPD 组合奖励的搭配策略,以及 PRM 投票如何参与;
- 跟随信号融合代码,把多个奖励来源合成一个可训练信号。
项目 6 · 部署态 Agent Skill 自进化系统(Memento-Skills)
观察 Agent 从失败轨迹中生成新 skill、评估、改进并复用,理解不改权重的能力增长路径。Memento-Skills 给出的是另一条路 —— Agent 上线后不重训也能持续变强:用 Skill 沉淀、路由、内化的闭环,把"参数学习"换成"外部能力库治理"。
- 拆 skill 发现、路由、执行、验证、回写和版本治理的工程链路;
- 跟随 Read-Execute-Reflect-Write 闭环看一个新 skill 从失败到沉淀的完整路径;
- 理解 skill 内化与外部能力库的边界:什么时候该把 skill 训进权重、什么时候应该保留为可审计版本。

课程目录
(点击 PREVIEW 查看课程简介)
- 章节概览
- 为什么用RL?Policy/RM/Critic/Reference四模型详解 (10:39)
- 从PPO到GRPO:组采样+相对优势+完整目标函数详解 (12:27)
- 告别奖励模型:DPO直接偏好优化完整拆解 (17:58)
- 从零看懂VeRL:工业级RL后训练框架的全局视图与六层架构 (11:30)
- DataProto与Single Controller:让分布式训练看起来像单进程的两块基石 (8:54)
- 训练路径全程拆解:从一条命令到一次完整PPO训练 (8:46)
- VeRL算法扩展机制揭秘:如何组合出PPO、GRPO、DAPO等十多种算法 (8:43)
- Reward Loop与Agent Loop:从PPO训练器迈向多轮工具调用的后训练运行时 (8:18)
- VeRL的当下与未来:架构演进、实验区与扩展点地图 (11:15)
- VeRL实战:基于Qwen3跑通GRPO强化学习训练 (12:45)
- VeRL实战:基于Qwen3跑通DPO中文偏好对齐 (10:13)
- 章节概览
- 多轮Agent到底该怎么训?Agentic RL的环境、数据与奖励闭环 (19:50)
- OpenClaw-RL与Agentic RL稳定训练实战逻辑,PPO、异步系统一次讲清 (18:42)
- OpenClaw-RL全系统拆解,Next-State Signal + 异步四环架构 + 三大核心算法 (20:37)
- OpenClaw-RL核心源码精讲,从Sample到PPO Loss到Combine的完整实 (17:11)
- Toolcall RL异步训练闭环全解,把rollout、actor、PRM拼成一条异步流水线 (8:38)
- 从SFT到ToolCall模型:Qwen3-0.6B + ReTool-SFT实战跑通 (23:19)
- RL强化学习训练全流程演示: Qwen3-0.6B + ReTool-RL (14:16)
- 用 PRM 跑通过程奖励训练,提升 Qwen3-0.6B 推理过程 (11:09)
- 章节概览
- Agent Skill 到底是什么?五种形态与五条边界 (7:27)
- Agent Skill 的问题-解法坐标:7 大痛点 × 8 类解法 (8:10)
- SkillRL 枢纽与双轨共演化的四条路径 (9:20)
- EvoSkill、Trace2Skill、SkillClaw:三种为自演化Agent加护栏的思路 (7:49)
- Skill 多了以后怎么办:Routing、SkillGraph 与大规模技能检索 (8:06)
- Skill是代码,LLM是处理器:Agent世界正在长出自己的LLVM (8:42)
- Skill 内化:把 Skill 训进模型参数,还是继续挂在外面? (7:42)
- 怎么选一条不踩坑的Skill路线?数据、延迟、场景、生态的四维决策框架 (9:18)
- 不动权重,Agent 也能越用越强:Memento-Skills 源码精讲 (19:34)
- Memento-Skills实战前准备:安装、配置与启动校验 (9:39)
- 从PDF生成任务入门Memento-Skills核心机制 (8:55)
- 打造自己的Skill:描述调优、脚本化与稳定执行 (22:36)
- 端到端自进化闭环:从能力缺口到Skill改进 (17:17)
- 每日AI资讯助手:实时抓取、评估与生成日报 (16:50)
课程内容概览
(请点击播放以下视频查看课程简介)
学习目标
这门课不是教你再搭一个 Agent Demo,而是帮你判断:一个 Agent 项目如何从"能跑"走到稳定、可评估、可训练、可上线。
1 .什么时候该上 RL?—— SFT、DPO、GRPO、PPO、Skill 和评测系统各自适合什么阶段,避免把所有问题都误判成"换算法"。
2 .奖励该怎么设计? —— 从可验证奖励、过程奖励、LLM-as-Judge 到混合奖励,判断奖励是否可靠、是否会被模型钻空子。
3 .长轨迹失败怎么归因?—— 多轮工具调用失败后,能判断问题在规划、参数、环境反馈、总结,还是 credit assignment 设计。
4 .训练系统哪里会失真? —— 理解 rollout、mask、PRM judge、异步训练、权重同步和样本新鲜度如何影响梯度和上线表现。
如果这 4 个问题正是你现在卡住的位置,这门课就在帮你直接补上。
建立 Agent RL 工程判断力
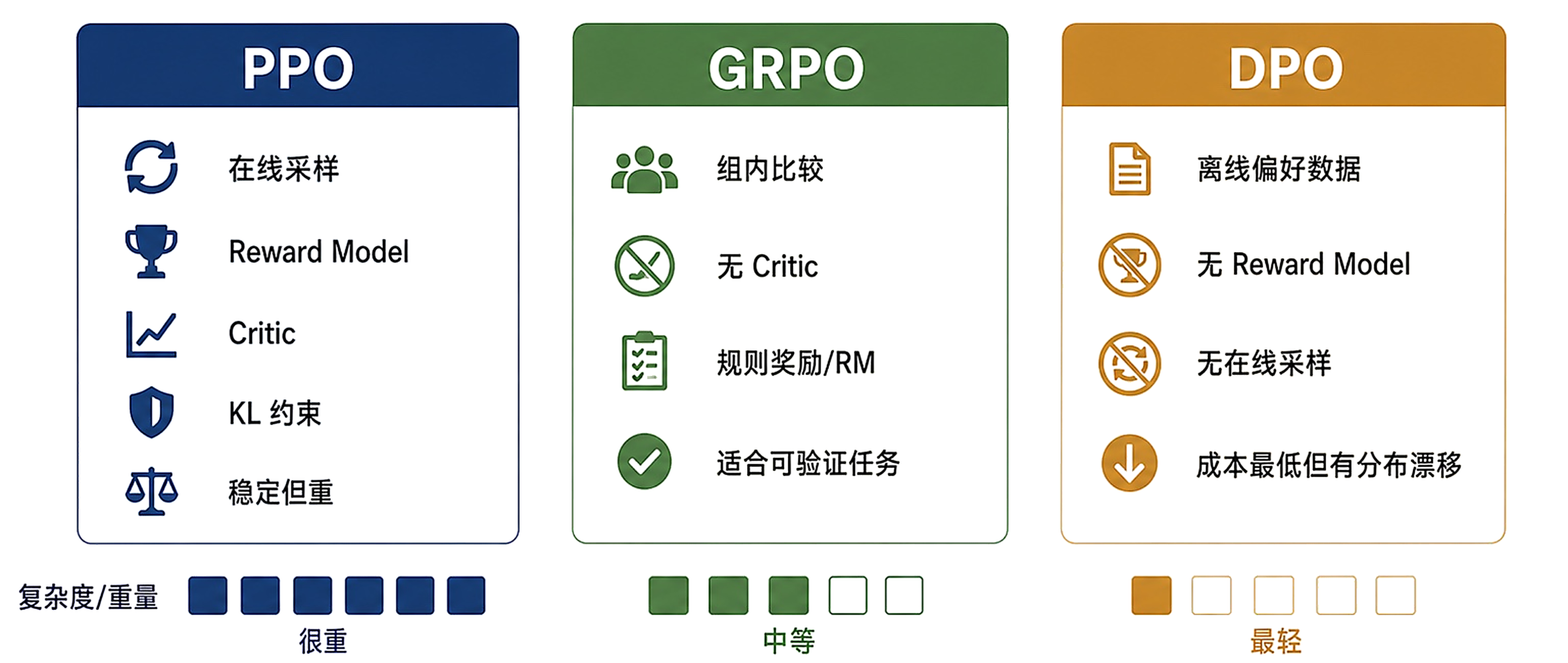
看懂 PPO、GRPO、DPO 的真实取舍
PPO 完整但重,GRPO 适合可验证任务,DPO 成本低但受离线偏好数据约束。课程会把算法放回反馈来源、奖励粒度、在线采样和系统成本里比较 —— 不是记公式,而是判断任务和系统成本。
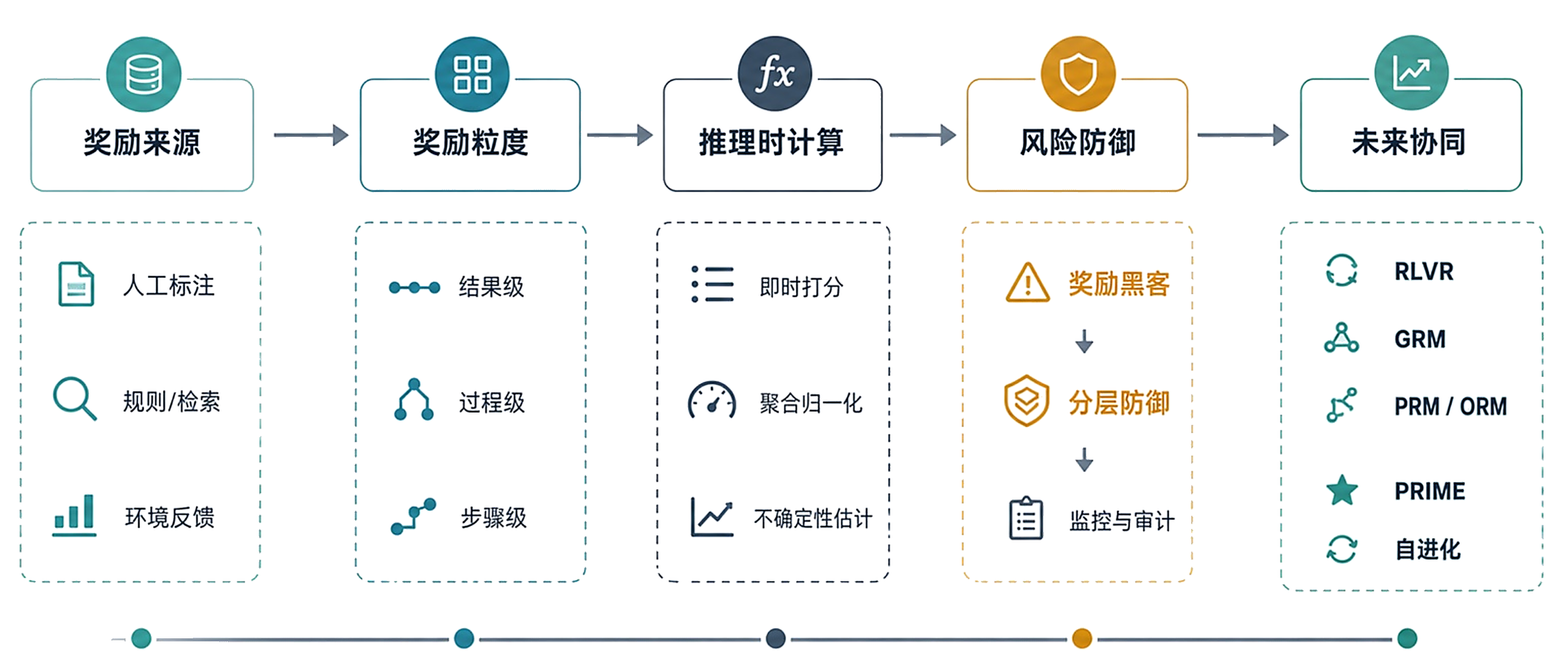
设计奖励,防止模型学会骗分
从 RLVR、ORM、PRM、GRM 到 PRIME,再到复合奖励、KL 约束、奖励模型集成、对抗样本和线上监控,把"造尺子"变成可落地的工程能力。
把多轮工具调用转成可训练反馈
Agent 失败不等于每一步都错。课程拆解 Agent-RRM、Reagent、next-state signal、PRM judge、loss mask 与 step span,处理长轨迹信用分配。
这门课适合你吗?
如果你只想用 API 搭一个简单工作流,这门课会显得过重。它面向的是已经遇到奖励难设计、多轮失败难归因、训练框架难读、上线评估不稳定的人。
如果你:
· 有 Python、深度学习、大模型应用或微调基础的算法工程师。
· 正在落地 Agent,被工具调用失败、奖励不稳和评估困难困住的开发者。
· 想读懂 VeRL、Reagent、OpenClaw-RL 等后训练系统的工程师。
· 希望用论文建立长期选型框架,而不是追逐单个新名词的研究者。
· 已经做过一版 Agent,想从"能跑"走到"能上线"的产品或项目负责人。
那这门课程就是为你而生的。
不建议:
· 完全没有 Python、PyTorch、Transformer 或大模型基础。
· 只想用 Prompt 和工具调用快速搭 Demo,不打算碰训练与源码。
· 期待 30 分钟速通 Agent RL,不愿跟着项目和论文建立判断。
· 希望直接拿到一个"开箱即用 SOTA 模型权重"而不是工程方法的同学。
更多精品课程
学习更多大模型相关精品课程,构建更完整的大模型能力体系。

一套系统化、生产级的大模型深度学习指南。

多模态大模型前沿算法及其应用,最新的研究成果与技术发展趋势。

大语言模型 LLM 和检索增强生成 RAG
理论与实战。
常见问题
一、支持的付款方式有哪些?
本网站支持以下付款方式:
- PayPal 付款
- 双币种或全币种的信用卡付款
- 通过淘宝或微信小店付款(淘宝和微信小店仅作为支付通道,课程仍在本网站学习)。
请参考《付款指南》,选择适合你的付款方式。
在淘宝或微信小店支付后,请发送订单号和用于注册学习账号的邮箱给在线客服,或通过公众号、微信 、Telegram 联系官方课程助理,我们将尽快处理你的订单并邀请你加入对应课程。(你可以提前注册账号,只需确保提供给我的邮箱与注册邮箱一致即可。点此查看《注册登陆指引》)
二、课程是否提供一对一指导?
本课程的定价仅包含:
- 全部课程视频的终身观看权限
-
配套资料的完整下载与后续更新
课程不包含一对一指导服务。但在时间允许的情况下,我会尽力为大家进行课程相关的问题的解答,帮助大家顺利学习。
精品课程内容经过反复打磨与完善,并配有详尽的资料,确保你高效掌握相关知识。目前已通过数百名同学的真实学习反馈,获得高度好评。
如果你在学习过程中有任何疑问,欢迎你:
- 参与精品课程后,根据课程前面的提示,加入 Discord 专属频道或微信群,在群内提问;
- 在对应课程视频下方评论区留言提问;
- 登录网站后,点击右上角头像 → 选择 “Contact” 给我发送邮件。
三、与在B站学习有什么区别?
精品课程在本网站与B站课堂同步上线,课程内容本身完全一致,区别主要体现在以下几个方面:
1.功能与课程资料呈现方式不同:
官网课程资料与视频内容同步展示,可在对应章节中预览并下载使用。B站以视频播放为主,请购买后通过私信发送课程名称或截图,以便获取对应课程资料并邀请你加入我们的 AI 学习圈。
2.发票开具说明:
本网站直接购买:将会自动收到一封收据邮件,请在你的注册邮箱中查看。
通过淘宝或微信小店支付:如需发票请直接联系在线客服即可开具。
B站购买:订单由B站平台统一管理,如需开具发票,请在B站后台订单中申请,或联系B站客服。
⚠️温馨提示(适用于 iOS 用户)
如果你使用 iPhone 或 iPad 访问 B站并购买课程,建议使用电脑端或手机浏览器访问我的B站课堂完成课程购买,避免额外支付 iOS 端加收的30%渠道费用。
四、什么时候购买最优惠?
答案是——如果你已经决定开始学习,现在就是最合适的时机。
精品课程一次购买,终身有效。除了偶尔的粉丝回馈活动,精品课程不会参与任何限时折扣或平台促销,价格始终保持公开透明。如果未来课程内容有更新和迭代,价格也会随之逐步上调。
我希望大家把有限的时间和精力花在真正有价值的学习上,而不是计算“活动价”上;希望大家购买课程,不是因为打折,而是因为它真的能让你成长、进步、变得更强。
如果你做过对比,能够透过花哨的宣传看清楚知识的本质,你应该会知道我的精品课程的性价比。你甚至可以通过学习我分享的免费公开课,就可以学到很多在其他地方需要付费才能学到的知识。
五、我是转行过来的,听说大模型很火,学完这个课程能不能直接上手?
实事求是的说,我并不建议你直接学习我的课程。我的精品课程专为AI技术领域的专业人才设计,课程内容紧随前沿技术,具有一定深度,并不是仅凭一步步跟随操作就能学会的简单教学。非科班出身或转行学习者可能会感到吃力。如果你决心深入学习 AI 技术,我真诚的建议你花一些时间,好好梳理一下,将一些相关的基础知识先理解和掌握。只有打好基础,一步步积累,才能真正与前沿技术接轨。
六、我可以每天问很多很多的问题吗?
我非常欢迎大家积极的学习和提问,但一定要问有价值的问题。对于那些通过AI或搜索引擎即可找到答案的问题,以及可以在B站或 YouTube 等平台免费学习的基础知识,我建议你主动学习和理解,这比直接提问更为高效。主动解决问题是 AI 技术学习者的基本能力,要尽快摸索出一套适合自己的高效学习方法,这样你才能在技术这条路上越走越远。
七、听说课程永久有效、后续还会进行更新,什么时候会更新?
作为一个终身学习的技术人,所有精品课程都会随着技术的发展以及我个人的技术积累为大家适时进行更新。由于时间精力有限,我会根据技术发展的成熟度以及个人工作安排来进行更新。大家可以关注网站课程页面,Discord 社区、以及公众号、 B站、YouTube 动态、邮箱推送等官方通知。